【SQL】SELECTの使い方を初心者向けに解説|SQL Server LocalDB+SSMSでデータ取得まで実践

SQLを学ぶうえで、最初に覚えるべき基本がSELECTです。
SELECTを使うと、データベースに保存されているデータを一覧表示したり、条件を指定して必要なデータだけを取り出したりできます。
この記事では、SQL Server LocalDBとSSMSを使って、実際にテーブルを作成し、データを登録し、SELECTでデータを取得するところまで解説します。
SQLの文法だけを読むのではなく、実際に手を動かして確認できる内容にしているので、SQL初心者の方でも流れを理解しやすいはずです。
SELECTは、SQLの中でも最も使用頻度が高い基本構文です。まずは「データを取り出す」操作を理解すると、INSERT、UPDATE、DELETEも学びやすくなります。
この記事でわかること
この記事では、SELECTを使ってデータを取得する基本操作を学びます。
具体的には、以下の内容がわかります。
- SQL Server LocalDBとSSMSを使った確認環境
- SELECTの基本構文
- テーブル作成とサンプルデータ登録の流れ
- 全件取得、列指定、条件指定の方法
- 並び替えや件数制限の使い方
- 初心者がつまずきやすいエラーと対処法
SQLを初めて触る方でも、順番に進めれば確認できる構成にしています。
前提環境
この記事では、Windows環境でSQL Server LocalDBとSSMSを使う前提で進めます。
バージョンは一例です。環境によって画面表示や細かい操作が異なる場合があります。
| 項目 | 内容 |
|---|---|
| OS | Windows 11 |
| データベース | SQL Server LocalDB |
| 管理ツール | SQL Server Management Studio(SSMS) |
| SQL Server | SQL Server 2022 LocalDB など |
| 使用言語 | SQL |
環境構築ができていない場合は、以下を参考にしてください。
また、C#.NETで実行したい方は本記事と以下の記事を見ながら試行してみてください。

完成イメージ
この記事の最終的なゴールは、SSMS上でSQLを実行し、社員データをSELECT文で取得できる状態にすることです。
最終的には、以下のようなデータを取得できるようになります。
| EmployeeId | EmployeeName | Department | Salary | HireDate |
|---|---|---|---|---|
| 1 | 山田太郎 | 営業部 | 300000 | 2022-04-01 |
| 2 | 佐藤花子 | 開発部 | 420000 | 2021-10-01 |
| 3 | 鈴木一郎 | 総務部 | 280000 | 2023-01-15 |
この記事では、単に一覧表示するだけではなく、
条件を指定して必要なデータだけを取り出す方法まで扱います。
たとえば、以下のような取得ができるようになります。
・全社員を一覧表示する
・名前と部署だけを表示する
・開発部の社員だけを表示する
・給与が30万円以上の社員を表示する
・入社日が新しい順に並び替える
SELECTの実践
ここからは、実際にSQL Server LocalDBとSSMSを使ってSELECT文を実行していきます。
上から順番に進めることで、同じ結果を確認できる構成にしています。
学習用データベースを作成する
まずは、SELECTを試すための学習用データベースを作成します。
既存のデータベースを触らず、練習用のデータベースを作ると安全です。
SSMSで新しいクエリを開き、以下のSQLを実行します。
CREATE DATABASE SampleSelectDb;実行後、左側のデータベース一覧を更新すると、SampleSelectDbが表示されます。
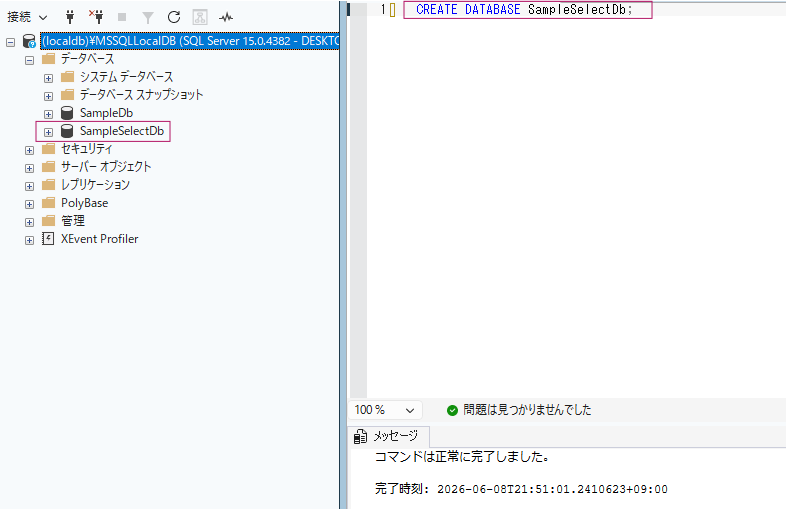
作成したデータベースを使うために、以下のSQLも実行します。
USE SampleSelectDb;これで、以降のSQLはSampleSelectDbに対して実行されます。
社員テーブルを作成する
次に、社員情報を保存するテーブルを作成します。
SELECTを試すには、取得対象となるテーブルとデータが必要です。
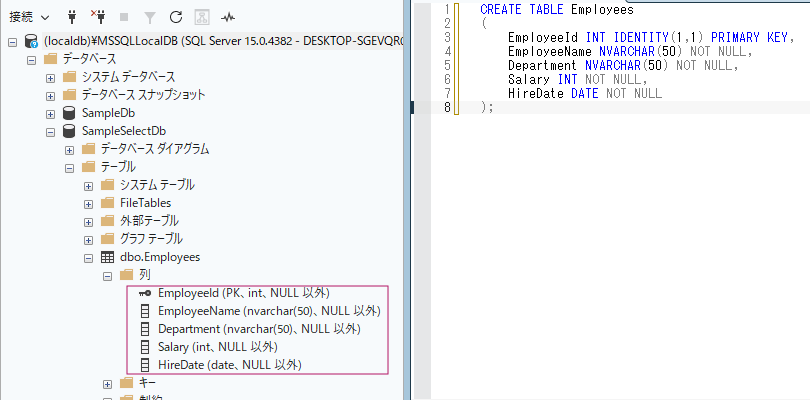
今回は、社員ID、社員名、部署、給与、入社日を持つEmployeesテーブルを作成します。
CREATE TABLE Employees
(
EmployeeId INT IDENTITY(1,1) PRIMARY KEY,
EmployeeName NVARCHAR(50) NOT NULL,
Department NVARCHAR(50) NOT NULL,
Salary INT NOT NULL,
HireDate DATE NOT NULL
);各列の役割は以下の通りです。
| 列名 | 内容 |
|---|---|
| EmployeeId | 社員ID |
| EmployeeName | 社員名 |
| Department | 部署名 |
| Salary | 給与 |
| HireDate | 入社日 |
EmployeeIdにはIDENTITYを指定しているため、データを追加すると自動で番号が入ります。
サンプルデータを登録する
次に、SELECTで取得するためのサンプルデータを登録します。
実際のデータが入っていないと、SELECTを実行しても結果は表示されません。
以下のSQLを実行してください。
INSERT INTO Employees
(
EmployeeName,
Department,
Salary,
HireDate
)
VALUES
(N'山田太郎', N'営業部', 300000, '2022-04-01'),
(N'佐藤花子', N'開発部', 420000, '2021-10-01'),
(N'鈴木一郎', N'総務部', 280000, '2023-01-15'),
(N'田中美咲', N'開発部', 450000, '2020-07-20'),
(N'高橋健', N'営業部', 350000, '2022-11-01'),
(N'伊藤葵', N'人事部', 310000, '2023-06-10');SQL Serverで日本語文字列を扱う場合は、文字列の前にNを付けています。
これは、Unicode文字列として扱うためです。
SELECTで全データを取得する
ここからSELECTを実行します。
まずは、Employeesテーブルの全データを取得します。
SELECTの基本は、どの列を、どのテーブルから取得するかを指定することです。
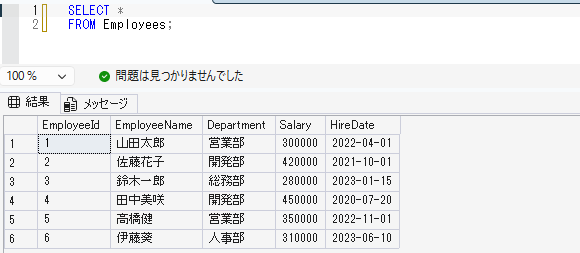
これはEmployeesテーブルに登録されているすべての列とすべての行が表示します。
SELECT *
FROM Employees;※アスタリスクは、すべての列を取得するという意味です。
実際に実行してみると、画像のように取得ができます。
学習中は便利ですが、実務では必要な列だけを指定することが多いです。
必要な列だけを取得する
次に、社員名と部署だけを取得してみます。
必要な列だけを指定すると、結果が見やすくなります。
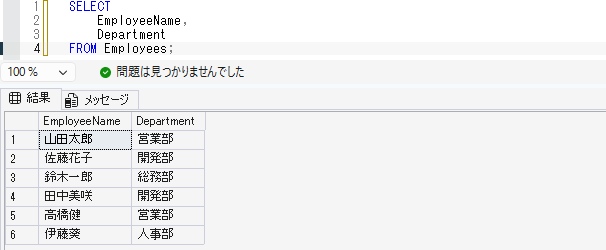
SELECT
EmployeeName,
Department
FROM Employees;このSQLでは、EmployeesテーブルからEmployeeNameとDepartmentだけを取得しています。すべての列が必要ない場合は、このように列名を指定します。
実務では、不要な列を取得しないことで、処理の負荷を抑えられる場合があります。
WHERE句で条件を指定する
次に、WHERE句を使って条件に合うデータだけを取得します。
WHERE句は、取得する行を絞り込むための条件指定です。
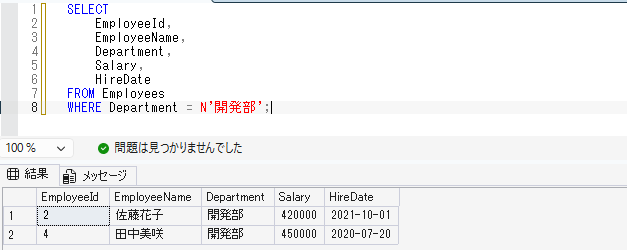
たとえば、開発部の社員だけを取得する場合は、以下のように書きます。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
WHERE Department = N'開発部';このSQLでは、Departmentが開発部のデータだけが表示されます。
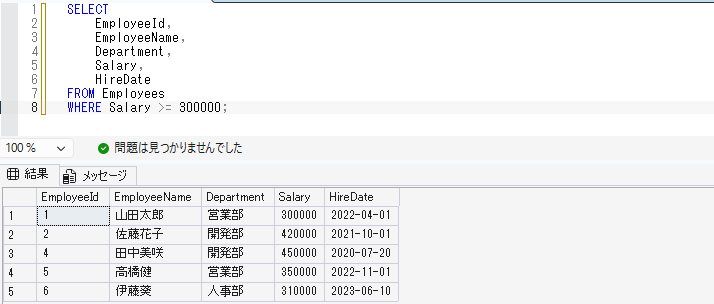
給与が30万円以上の社員を取得する場合は、以下のように書きます。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
WHERE Salary >= 300000;数値を比較する場合は、文字列のようにシングルクォーテーションで囲む必要はありません。
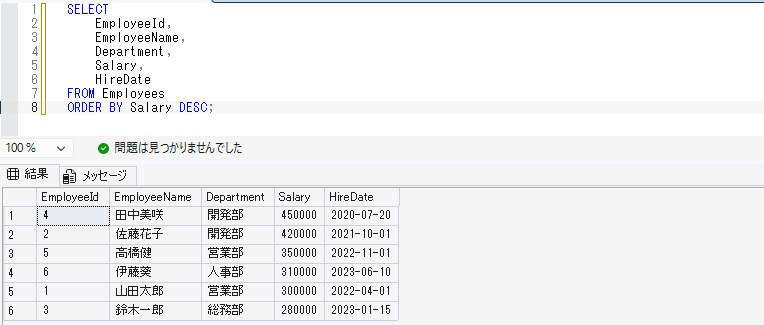
ORDER BY句で並び替える
次に、ORDER BY句を使って取得結果を並び替えます。
ORDER BY句を使うと、表示順を指定できます。
給与が高い順に表示する場合は、以下のように書きます。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
ORDER BY Salary DESC;DESCは降順、つまり大きい順を意味します。
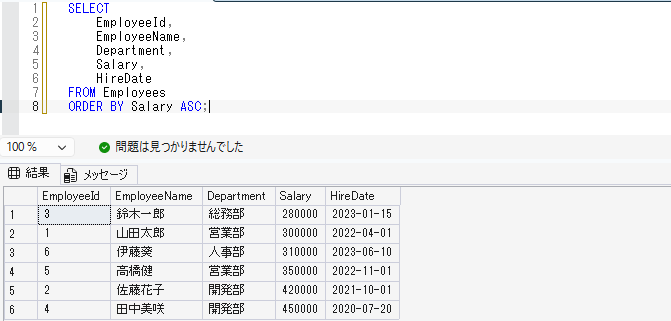
逆に、小さい順に並び替えたい場合はASCを使います。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
ORDER BY Salary ASC;ASCは省略できますが、初心者のうちは明示しておくと読みやすいです。
TOP句で取得件数を制限する
次に、TOP句を使って取得件数を制限します。
大量データを扱う場合、最初から全件取得しないことが重要です。
給与が高い順に上位3件だけ取得する場合は、以下のように書きます。
SELECT TOP 3
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
ORDER BY Salary DESC;このSQLでは、給与が高い順に並び替えたあと、上位3件だけを表示します。
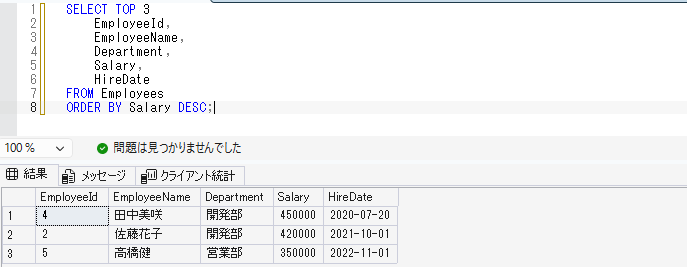
SQL ServerではTOPを使いますが、MySQLではLIMITを使うなど、データベースによって書き方が異なる場合があります。
LIKE句で部分一致検索する
次に、LIKE句を使って名前の一部で検索します。
LIKE句は、文字列の一部が一致するデータを探すときに使います。
たとえば、社員名に「田」が含まれる社員を取得する場合は、以下のように書きます。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
WHERE EmployeeName LIKE N'%田%';※パーセント記号は、任意の文字列を表します。
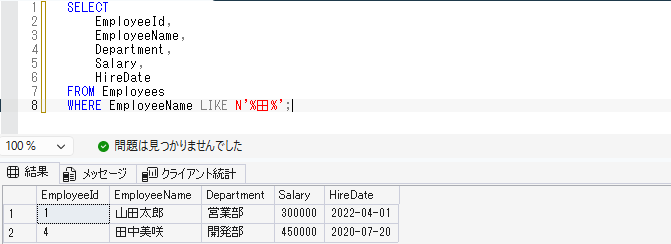
今回のように前後に付けると、「田」を含むデータを検索できます。
よくあるエラー・注意点
SELECT自体はシンプルですが、初心者のうちは接続先やテーブル名、文字列の書き方でつまずきやすいです。
エラーが出た場合は、SQL文だけでなく接続先データベースも確認してください。
| エラー・現象 | 主な原因 | 対処法 |
|---|---|---|
| データベースに接続できない | LocalDBが入っていない、サーバー名が違う | サーバー名が正しいか確認する |
| SampleSelectDbが見つからない | データベース作成SQLを実行していない | CREATE DATABASEを実行する |
| Employeesが見つからない | 使用中のデータベースが違う | USE SampleSelectDbを実行する |
| 日本語が文字化けする | 文字列の扱いが適切でない | SQL ServerではN付き文字列を使う |
| SELECT結果が空になる | 条件に一致するデータがない | WHERE条件を見直す |
| 並び順が想定と違う | ORDER BYを指定していない | ORDER BY句を追加する |
| 文字列条件でエラーになる | シングルクォーテーションがない | 文字列をシングルクォーテーションで囲む |
テーブル名や列名の入力ミスに注意する
SQLでは、テーブル名や列名を間違えるとエラーになります。
特に英単語の複数形や大文字小文字の違いは確認しておきましょう。
今回のテーブル名はEmployeesです。
EmployeeではなくEmployeesになっている点に注意してください。
環境によっては大文字小文字を区別する設定になっている場合もあります。
WHERE句の条件に注意する
WHERE句の条件が間違っていると、エラーにはならなくても結果が0件になることがあります。
エラーが出ないのにデータが表示されない場合は、条件が厳しすぎる可能性があります。
たとえば、以下のSQLは営業部のデータを取得します。
SELECT
EmployeeId,
EmployeeName,
Department,
Salary,
HireDate
FROM Employees
WHERE Department = N'営業部';もし条件に存在しない部署名を指定すると、結果は空になります。
その場合は、まず全件取得して、実際に登録されている値を確認してください。
SELECT *
FROM Employees;アスタリスクの使いすぎに注意する
アスタリスクを使うと、すべての列を簡単に取得できます。
学習中は便利ですが、実務では必要な列だけ取得する方が望ましいです。
SELECT *
FROM Employees;テーブルの列が少ないうちは問題になりにくいですが、列数やデータ量が増えると、不要なデータまで取得してしまいます。
実務では、以下のように必要な列だけを書くことが多いです。
SELECT
EmployeeName,
Department,
Salary
FROM Employees;SELECTは「とりあえず全件取得」から始めても問題ありません。ただし、実務では必要な列と条件を指定して、無駄な取得を減らす意識が重要です。
まとめ
今回は、SQL Server LocalDBとSSMSを使って、SELECTの基本的な使い方を解説しました。
SELECTは、SQLを学ぶうえで最初に押さえるべき重要な構文です。
この記事で行ったことを整理すると、以下の通りです。
- SSMSからSQL Server LocalDBに接続した
- 学習用データベースを作成した
- Employeesテーブルを作成した
- サンプルデータを登録した
- SELECTで全件取得、列指定、条件指定を確認した
- ORDER BY、TOP、LIKEの基本を確認した
- よくあるエラーと注意点を整理した
SELECTが理解できると、データベースの中身を確認できるようになります。
次に学ぶなら、INSERT文、UPDATE文、DELETE文に進むと、データの追加、更新、削除まで一通り扱えるようになります。



サイトアイコン-2-150x150.png)













